SPDC: A Super-Point and Point Combining Based Dual-Scale Contrastive Learning Network for Point Cloud Semantic Segmentation
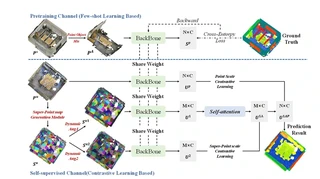 SPDC architecture with dual-scale contrastive learning (super-point and point levels)
SPDC architecture with dual-scale contrastive learning (super-point and point levels)Highlights
- SPDC Network: A dual-scale contrastive learning framework operating at both super-point and point levels to reduce reliance on annotated data for point cloud semantic segmentation.
- Super-Point Assisted Learning: Introduces super-point maps to expand the receptive field and provide multi-scale feature representation, addressing insufficient feature extraction in standard contrastive learning.
- PointObjectMix (POM): Novel object-level data augmentation method analogous to CutMix, solving sample imbalance while preserving structural semantic information of point cloud objects.
- Dynamic Data Augmentation (DDA): Learnable augmentation module for super-point maps using MLP and noise signals to generate diverse positive samples for contrastive learning.
- State-of-the-Art Performance: Achieves 63.3% mIoU on S3DIS dataset in the self-supervised setting, outperforming existing unsupervised methods (e.g., CrossPoint 58.4%, PointMatch 63.4%).
Methodology
The proposed SPDC framework consists of two main channels:
1. Pre-training Channel (Few-shot Learning)
- PointObjectMix (POM): Mixes objects from different scenes to create new training samples, balancing categories while maintaining geometric integrity
- Lightweight Backbone: Uses DGCNN with EdgeConv for local feature extraction plus Self-attention for global context modeling
- Few-shot Pre-training: Trains on less than 10% of ScanNetV2 data (100 scenes) to provide initial weights for downstream tasks
2. Self-supervised Channel (Contrastive Learning)
- Super-Point Generation: Converts point clouds into super-point maps using a lightweight PointNet-based network with learnable association mapping
- Dynamic Data Augmentation (DDA): Generates augmented views via learnable affine transformations parameterized by MLPs and Gaussian noise
- Dual-Scale Contrastive Learning:
- Super-point level: Contrastive learning between augmented super-point features (U¹ᴬ vs U²)
- Point level: Contrastive learning between original point features and back-projected super-point features (Uᴾ vs U¹ᴬᴾ)
- Uses NT-Xent loss with cosine similarity
Experimental Results
Dataset: S3DIS (Stanford 3D Indoor Scene Dataset) - 271 rooms, 13 categories
Comparison with Self-supervised Methods:
| Method | Supervision | mIoU (%) |
|---|---|---|
| DGCNN | 100% | 56.1 |
| CrossPoint | 0% | 58.4 |
| PointSmile | 0% | 58.9 |
| PointMatch | 0.1% | 63.4 |
| SPDC (Completed) | 0% | 63.3 |
Ablation Study Results:
| Configuration | mIoU (%) |
|---|---|
| No pre-training | 51.3 |
| No super-point | 56.7 |
| No self-attention | 59.6 |
| Full SPDC | 63.3 |
Key findings:
- Pre-training channel provides crucial initialization for specific downstream tasks (+5.4% mIoU)
- Super-point features significantly improve segmentation by expanding receptive field (+2.9% mIoU)
- Self-attention layer enhances global context modeling (+3.7% mIoU)

I am currently a Ph.D. candidate at the Ai4City-Lab, Urban Governance and Design Thrust, Society Hub, The Hong Kong University of Science and Technology (Guangzhou), under the supervision of Prof. Wufan Zhao and Prof. Yuan Liu. Prior to this, I obtained my Master’s degree from the School of Geospatial Engineering and Science, Sun Yat-sen University, where I was advised by Prof. Wuming Zhang and Prof. Yiping Chen.
My research focuses on 3D visual perception, intelligent interpretation and processing of point cloud data, and multi-modal urban foundation models. I am particularly interested in bridging geometric understanding with semantic reasoning in large-scale urban environments, with an emphasis on open-vocabulary learning, training-free paradigms, and cross-modal fusion between 2D and 3D data.
My goal is to develop scalable, interpretable, and generalizable AI systems for urban analysis, enabling applications such as digital twin construction, urban scene understanding, and intelligent infrastructure management.