DSTI-Net: A Dynamic Spatial–Temporal Interaction Network With Semantic Guidance for 2-D and 3-D Change Detection
Mar 2, 2026·,,,
Tengxi Wang
Shuai Zhang
Mengmeng Li
Wufan Zhao
Corresponding author
·
2 min read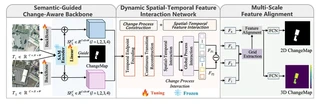 DSTI-Net architecture with SGCA backbone, DSTI module, and MSA module
DSTI-Net architecture with SGCA backbone, DSTI module, and MSA moduleAbstract
Change detection is a key technique for monitoring spatial and structural changes in urban environments. With the progression of urbanization, such changes increasingly manifest in both planar and vertical structures, particularly in building morphology. However, current methods insufficiently explore the relationship between 2-D semantics and 3-D information, resulting in poor discrimination of subtle changes in semantically ambiguous regions and limited generalization under complex scenarios. To address these challenges, we propose dynamic spatial–temporal interaction (DSTI)-Net, a multitask framework for joint 2-D semantic and 3-D structural change detection. Inspired by human visual perception, the semantic-guided change-aware (SGCA) backbone integrates a segment anything model (SAM) encoder to guide multiscale semantic feature extraction, enabling the network to focus on spatially relevant variations in change regions. To enable cross-dimensional feature interaction, the DSTI module explicitly captures spatial–temporal dependencies between 2-D semantic structures and 3-D geometric representations through 3-D convolution and attention mechanisms, thereby improving structural perception. In addition, the multiscale feature alignment (MSA) module refines feature fusion, ensuring semantic consistency and enhancing the delineation of fine-grained changes. Experimental results on the 3DCD and SMARS datasets demonstrate that DSTI-Net achieves state-of-the-art (SOTA) performance. On the 3DCD dataset, it achieves an F1 of 67.09% and a cRMSE of 4.89m. On the SMARS dataset, it further demonstrates strong cross-resolution generalization.
Type
Publication
IEEE Transactions on Geoscience and Remote Sensing, vol. 64, art. no. 4404814
Highlights
- DSTI-Net: A unified multitask framework for simultaneous 2-D semantic and 3-D structural change detection using only bitemporal optical remote sensing images.
- Semantic-Guided Change-Aware (SGCA) Backbone: Integrates frozen SAM (Segment Anything Model) encoder to provide structured semantic guidance, enhancing feature representation in change regions and suppressing background noise.
- Dynamic Spatial–Temporal Interaction (DSTI): Novel 3-D convolution-based module that constructs temporal endpoints and intermediate transition states to explicitly model bitemporal structural evolution, enabling effective 2D–3D feature collaboration.
- State-of-the-Art Performance: Achieves F1 of 67.09% and cRMSE of 4.89m on 3DCD dataset, outperforming existing multitask methods (MTBIT, CSCLNet) and foundation model-based approaches (SCD-SAM).
- Strong Generalization: Demonstrates robust cross-resolution transferability (0.3m → 0.5m) and cross-domain generalization (SParis → SVenice) on SMARS dataset.
Methodology
The DSTI-Net architecture comprises three key modules:
1. Semantic-Guided Change-Aware (SGCA) Backbone
- Utilizes ResNet backbone for multiscale feature extraction from bitemporal images
- Integrates frozen SAM encoder (ViT-B) to extract semantic representations
- Employs change-map supervision during training to guide SAM attention toward change-relevant regions
- Enhances discriminability of change regions while suppressing redundant background information
2. Dynamic Spatial–Temporal Interaction (DSTI) Module
- Constructs 4-D temporal representation (T×C×H×W) by stacking bitemporal features
- Uses 3-D convolutions to extract endpoint features and generate intermediate transition representations
- Applies convolutional-attention blocks (Pointwise→Depthwise→Pointwise→Self-Attention) to capture spatial–temporal dependencies
- Enables explicit modeling of structural evolution between time steps, facilitating joint 2-D and 3-D representation learning
3. Multiscale Feature Alignment (MSA) Module
- Adopts grid-based strategy to divide features into local blocks
- Applies self-attention mechanism for adaptive aggregation of grid features
- Integrates SE (Squeeze-and-Excitation) attention for channel-wise feature recalibration
- Refines fusion of high-level and low-level features to improve detection of fine-grained changes
Experimental Results
Datasets:
- 3DCD: Real-world urban change detection dataset with bitemporal optical images (2010/2017) and DSM annotations
- SMARS: Simulated urban dataset (Paris/Venice) with 0.3m and 0.5m resolutions for cross-resolution evaluation
Quantitative Results on 3DCD:
| Method | F1 (%) | IoU (%) | cRMSE (m) |
|---|---|---|---|
| MTBIT | 63.29 | 46.29 | 5.25 |
| CSCLNet | 65.58 | 48.78 | 5.44 |
| SCD-SAM | 65.38 | 48.67 | 5.03 |
| DSTI-Net | 67.09 | 50.47 | 4.89 |
Key Findings:
- Ablation studies validate the contribution of each module: SGCA improves semantic awareness, DSTI enhances structural modeling (cRMSE reduction of 0.22m), and MSA refines fine-grained detection
- Cross-resolution transfer (0.3m → 0.5m): Maintains F1 of 91.72% and achieves lowest cRMSE (6.23m) among compared methods
- Cross-domain transfer (SParis → SVenice): Achieves F1 of 81.90% and cRMSE of 12.48m, significantly outperforming MTBIT and CSCLNet
- Inference time: 0.24s per image (real-time capable) with 13.87M trainable parameters