Learning point cloud context information based on 3D transformer for more accurate and efficient classification
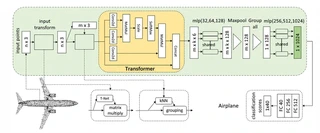 Framework integration showing T-Net, kNN grouping, and 3D transformer modules
Framework integration showing T-Net, kNN grouping, and 3D transformer modulesHighlights
- Novel 3D Transformer Architecture: First to integrate T-Net, kNN grouping, and 3D transformer modules for point cloud classification, addressing the limitation of independent point feature learning in traditional methods.
- Local Context Enhancement: Utilizes transformer attention mechanism to learn the importance differences between points in local neighborhoods, establishing relationships among neighboring points rather than treating them independently.
- High Accuracy with Efficiency: Achieves 92.2% overall accuracy on ModelNet40 (89.9% average class accuracy) and 93.8% on ModelNet10, outperforming PointNet (89.2%) and PointNet++ (90.7%) while maintaining low computational complexity.
- Lightweight Design: Requires only 2.1 million parameters and 470 million FLOPs/sample—less than one-third the parameters of PointNet++ (1.48M vs efficient design) with 1.5% higher accuracy.
- Robust to Data Sparsity: Demonstrates superior performance under random point dropout scenarios compared to PointNet, PointNet++, and DGCNN, maintaining accuracy even with 64-512 input points.
Methodology
The proposed classification framework consists of four main stages:
Input Transformation (T-Net):
- Learns an affine transformation matrix to align input point clouds
- Reduces sensitivity to rigid transformations and permutation
- Acts as position encoding equivalent for unordered point sets
- Improves robustness to input order before feature extraction
Local Neighborhood Construction (kNN):
- Furthest Point Sampling (FPS): Samples m points (640) from input n points (1024) as centroids
- k-Nearest Neighbor grouping: Selects k neighbors (k=16) for each centroid
- Constructs local point sets with dimension m × k × 3 suitable for sequence learning
- Better generalization of local structure compared to independent point processing
3D Transformer Module:
- Attention Mechanism: Calculates Query (Q), Key (K), Value (V) using Conv2d layers
- Context Learning: Learns influence scores of each point on others in the local neighborhood
- Feature Enhancement: Highlights points contributing more to local structure
- Parallel Computing: Supports efficient parallel attention calculation unlike sequential methods
- Skip Connection: Concatenates transformer output with original coordinates before MLP
Feature Aggregation and Classification:
- MLP layers: 32→64→128 dimensions for local features, 256→512→1024 for global features
- MaxPooling: Aggregates local features to global representation
- Fully Connected layers: 1024→512→256→40 (ModelNet40 classes)
- Final classification scores with softmax
Datasets
ModelNet40:
- Source: Princeton University CAD model dataset
- Training set: 9,843 shapes
- Test set: 2,468 shapes
- Input: 1,024 points per model (x, y, z coordinates)
- Classes: 40 categories (airplane, chair, car, etc.)
- Metrics: Overall accuracy (OA) and average class accuracy
ModelNet10 (Subset of ModelNet40):
- Total samples: 4,899 CAD models
- Training set: 3,991 samples
- Test set: 908 samples
- Classes: 10 categories
- Purpose: Benchmark for point cloud classification with fewer classes
Experimental Results
Classification Performance Comparison (ModelNet40):
| Method | Input Type | Views | Avg. Class Acc (%) | Overall Acc (%) |
|---|---|---|---|---|
| PointNet (baseline) | Point | 1 | 72.6 | 77.4 |
| PointNet | Point | 1 | 86.2 | 89.2 |
| PointNet++ | Point | 1 | - | 90.7 |
| KDNet (DEPTH 15) | Point | 1 | - | 91.8 |
| Point-PlaneNet | Point | 1 | - | 92.1 |
| ReducedPointNet++ | Point | 1 | - | 92.1 |
| Point Transformer | Point | 1 | - | 92.9 |
| Ours | Point | 1 | 89.9 | 92.2 |
Classification Performance (ModelNet10):
| Method | Input | Views | Avg. Class Acc (%) |
|---|---|---|---|
| 3DShapeNets | Volume | 1 | 83.54 |
| VoxNet | Volume | 12 | 92.00 |
| VSL | Volume | 1 | 93.10 |
| PointNet | Point | 1 | 77.60 |
| G3DNet | Point | 1 | 93.10 |
| Primitive-GAN | Point | 1 | 92.20 |
| Ours | Point | 1 | 93.80 |
Computational Efficiency:
| Method | Parameters | FLOPs/sample |
|---|---|---|
| PointNet | 3.5 million | 440 million |
| PointNet++ | 1.48 million | 1,684 million |
| Subvolume | 16.6 million | 3,633 million |
| MVCNN | 60.0 million | 62,057 million |
| Ours | 2.1 million | 470 million |
Ablation Study Results (ModelNet40):
| T-Net | kNN | Transformer | Overall Acc (%) | Improvement |
|---|---|---|---|---|
| ✗ | ✗ | ✗ | 88.5 | Baseline |
| ✓ | ✗ | ✗ | 89.2 | +0.7% |
| ✓ | ✓ | ✗ | 90.7 | +1.5% |
| ✓ | ✓ | ✓ | 92.2 | +1.5% |
Hyperparameter Analysis:
- Optimal neighbor points (k): 16 points (92.2% accuracy) vs. 8 points (91.5%) vs. 32 points (91.6%)
- Optimal sampling points: 640 points (92.2%) vs. 512 (91.6%) vs. 768 (91.2%)
- Optimal learning rate: 0.001 (92.2%) vs. 0.0005 (91.1%) vs. 0.002 (91.4%)
Key Findings
Module Effectiveness:
- T-Net improves accuracy by 0.7% by addressing point cloud disorder
- kNN grouping improves accuracy by 1.5% by enabling local structure learning
- 3D Transformer improves accuracy by another 1.5% by modeling point relationships within neighborhoods
Robustness to Sparsity:
- When testing with reduced input points (1024→512→256→128→64), the method shows gradual degradation but outperforms PointNet, PointNet++, and DGCNN at all sparsity levels
- At 64 points, maintains ~80% accuracy compared to PointNet’s ~60% and DGCNN’s failure
Critical Points Visualization:
- Transformer assigns greater weights to edge information and structural boundaries
- Critical point sets (high-attention points) concentrate on discriminative geometric features (e.g., airplane wings, chair legs) rather than uniform surfaces
Efficiency vs. Accuracy Trade-off:
- Achieves better accuracy than PointNet++ (92.2% vs 90.7%) with fewer parameters (2.1M vs computational efficiency advantage)
- FLOPs (470M) comparable to PointNet (440M) despite superior performance
- Suitable for real-time applications requiring both accuracy and efficiency
Attention Mechanism Benefits:
- Unlike CNNs that treat neighboring points independently, the transformer establishes explicit relationships between centroid and neighbors
- Attention weights adaptively highlight structurally important points in local neighborhoods
- Parallel computation capability maintains training efficiency despite attention overhead

I am currently a Ph.D. candidate at the Ai4City-Lab, Urban Governance and Design Thrust, Society Hub, The Hong Kong University of Science and Technology (Guangzhou), under the supervision of Prof. Wufan Zhao and Prof. Yuan Liu. Prior to this, I obtained my Master’s degree from the School of Geospatial Engineering and Science, Sun Yat-sen University, where I was advised by Prof. Wuming Zhang and Prof. Yiping Chen.
My research focuses on 3D visual perception, intelligent interpretation and processing of point cloud data, and multi-modal urban foundation models. I am particularly interested in bridging geometric understanding with semantic reasoning in large-scale urban environments, with an emphasis on open-vocabulary learning, training-free paradigms, and cross-modal fusion between 2D and 3D data.
My goal is to develop scalable, interpretable, and generalizable AI systems for urban analysis, enabling applications such as digital twin construction, urban scene understanding, and intelligent infrastructure management.