Point and voxel cross perception with lightweight cosformer for large-scale point cloud semantic segmentation
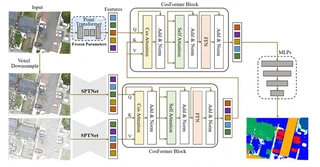 PVCFormer architecture overview with CosFormer Blocks
PVCFormer architecture overview with CosFormer Blocks> [!NOTE] > Click the Cite button above to demo the feature to enable visitors to import publication metadata into their reference management software.
Highlights
- PVCFormer: A novel point-and-voxel cross-perception network designed to effectively broaden the receptive field and improve object segmentation at various resolutions using cross-attention mechanisms.
- Lightweight Architecture: Introduction of CosFormer into point cloud processing to simplify computational complexity of transformers, reducing training time from 1200s to 800s per iteration without accuracy loss.
- SYSU9 Dataset: A new large-scale aerial point cloud dataset comprising approximately 200 million points, encompassing nine distinct feature classes and spanning over 7 square kilometers (Zhuhai campus of Sun Yat-sen University).
- State-of-the-art Performance:
- SensatUrban: 92.4% OA, 61.5% mIoU
- DALES: 94.6% OA, 73.6% mIoU
- SYSU9: 91.1% OA, 62.4% mIoU
Methodology
The PVCFormer architecture consists of three main components:
Point-level Feature Extraction: Utilizes Point Transformer with frozen pre-trained parameters to extract fine-grained point features serving as Query (Q) in the cross-attention mechanism.
Voxel-level Feature Extraction (SPTNet Encoder):
- Multi-resolution voxel sampling (e.g., 0.02m and 0.2m)
- Sparse convolution blocks for local feature extraction
- Transformer blocks for global context modeling
- Outputs serve as Key (K) and Value (V)
CosFormer Block:
- Cross-Attention: Fuses point and voxel features across different scales
- Cos-Attention Mechanism: Replaces traditional softmax attention with cosine-based linear attention, reducing complexity from O(N²d) to O(Nd²)
- Self-Attention & FFN: Standard transformer components for feature refinement
SYSU9 Dataset
A new benchmark dataset for large-scale outdoor point cloud semantic segmentation:
- Location: Zhuhai campus of Sun Yat-sen University
- Size: ~200 million points, 7 km² area
- Acquisition: RIEGL VUX-1LR UAV LiDAR (150m flight height, 400kHz scan frequency)
- Categories (9 classes):
- Roads
- Sidewalks
- Natural ground
- Trees
- Grass
- Vehicles
- Buildings
- Transportation facilities
- Man-made terrain
Experimental Results
Quantitative comparison on three benchmark datasets:
SensatUrban Dataset:
| Method | OA (%) | mIoU (%) |
|---|---|---|
| RandLA-Net | 89.8 | 52.7 |
| KPConv | 93.2 | 57.6 |
| LCPFormer | 93.5 | 63.4 |
| PVCFormer-CA | 92.4 | 61.5 |
| PVCFormer-SA | 93.8 | 62.4 |
DALES Dataset:
| Method | mIoU (%) |
|---|---|
| KPConv | 81.1 |
| SPT | 79.6 |
| PVCFormer-CA | 73.6 |
| PVCFormer-SA | 79.6 |
SYSU9 Dataset:
| Method | OA (%) | mIoU (%) |
|---|---|---|
| SparseConv | 89.7 | 56.7 |
| RandLA-Net | 44.2 | 34.6 |
| PVCFormer-CA | 91.1 | 62.4 |
| PVCFormer-SA | 92.7 | 64.1 |
Key Findings
- Cross-attention Efficacy: Cross-attention between point and voxel features improves mIoU by 18.7% compared to voxel-only methods.
- Pre-training Importance: Random initialization of Query leads to convergence failure; pre-trained Point Transformer is crucial.
- Efficiency Gains: CosFormer reduces per-iteration time by 33% (1200s → 800s) compared to standard self-attention while maintaining comparable accuracy.
- Small Object Detection: The method shows particular strength in detecting “Parking” and “Rail” categories due to cross-scale perception.

I am currently a Ph.D. candidate at the Ai4City-Lab, Urban Governance and Design Thrust, Society Hub, The Hong Kong University of Science and Technology (Guangzhou), under the supervision of Prof. Wufan Zhao and Prof. Yuan Liu. Prior to this, I obtained my Master’s degree from the School of Geospatial Engineering and Science, Sun Yat-sen University, where I was advised by Prof. Wuming Zhang and Prof. Yiping Chen.
My research focuses on 3D visual perception, intelligent interpretation and processing of point cloud data, and multi-modal urban foundation models. I am particularly interested in bridging geometric understanding with semantic reasoning in large-scale urban environments, with an emphasis on open-vocabulary learning, training-free paradigms, and cross-modal fusion between 2D and 3D data.
My goal is to develop scalable, interpretable, and generalizable AI systems for urban analysis, enabling applications such as digital twin construction, urban scene understanding, and intelligent infrastructure management.