SPTNet: Sparse Convolution and Transformer Network for Woody and Foliage Components Separation From Point Clouds
 SPTNet architecture overview showing SpConv and Transformer blocks
SPTNet architecture overview showing SpConv and Transformer blocksHighlights
- Novel Hybrid Architecture: First network to combine Sparse Convolution (SpConv) with Transformer blocks for tree component separation, balancing local feature extraction efficiency with global context modeling capabilities.
- Pure Geometry-Based Approach: Uses only XYZ coordinates without relying on radiometric features (LRI), ensuring sensor-agnostic generalization across different LiDAR devices and wavelengths.
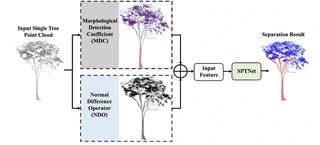
- Adaptive Geometric Features: Introduces two innovative feature blocks—Morphological Detection Coefficient (MDC) and Normal Difference Operator (NDO)—with adaptive radius determination strategies (minimum entropy and Otsu methods) to eliminate manual parameter tuning.
- State-of-the-Art Performance: Achieves 94.69% OA and 89.96% mIoU on large tropical tree dataset (15 species), outperforming FWCNN by 0.43% OA and 0.72% mIoU.
- High Efficiency: Training requires only 8 seconds per epoch with 48 epochs to convergence (vs. 15-45s/epoch for competing methods), and model size is less than 1/3 of PointNet++.
Methodology
The proposed SPTNet consists of three main components:
Geometric Feature Extraction (Preprocessing):
- MDC (Morphological Detection Coefficient): Characterizes local point distribution patterns using eigenvalues of covariance matrix. Values > 0.5 indicate linear distribution (woody), < 0.5 indicate planar distribution (foliage). Adaptive radius determined via minimum entropy principle.
- NDO (Normal Difference Operator): Measures normal vector variations within neighborhoods. Woody components show larger normal differences (cylindrical structure) vs. foliage (planar structure). Adaptive radius determined via Otsu thresholding.
- Input Representation: 7-dimensional vector (XYZ + MDC + NDO) organized in voxel-hash structure.
Network Architecture (UNet-based Encoder-Decoder):
- Encoder: 5 SpConv blocks (local feature extraction) + 5 Transformer blocks (global context aggregation)
- SpConv Block: 3 SubMConv layers + 1 SpConv downsampling layer with skip connections
- Transformer Block: Multi-head self-attention (8 heads) with skip connections from SpConv features
- Decoder: 4 inverse SpConv blocks for upsampling and dimensionality reduction
- Output: Linear layer for binary classification (woody vs. foliage)
- Encoder: 5 SpConv blocks (local feature extraction) + 5 Transformer blocks (global context aggregation)
Data Organization:
- Voxelization: 0.02m voxel size with average pooling for point-to-voxel mapping
- Sparse Convolution: Exploits data sparsity to reduce computational cost while preserving geometric details
- Augmentation: Random sampling (density variation) + rotation (< 45°) for training robustness
Datasets
Comprehensive validation across diverse forest environments:
| Dataset | Type | Species | Samples | Characteristics |
|---|---|---|---|---|
| Spruce | Real | Picea | Multiple | Coniferous |
| Aspen | Real | Populus | Multiple | Broadleaf |
| Poplar | Real | Populus | Multiple | Broadleaf |
| Birch | Real | Betula | Multiple | Broadleaf |
| Pine | Real | Pinus | Multiple | Coniferous |
| Maple | Real | Acer | Multiple | Broadleaf |
| Larch | Simulated | Larix | 100 | Synthetic (Helios++) |
| Tropical | Real | 15 species | 61 trees | Cameroon, 8.7-53.6m height |
- Data Sources: Canada, Finland, Cameroon (real); OnyxTree simulation (synthetic)
- Sensors: Riegl VZ-1000, various TLS devices
- Annotation: Manual labeling for woody/foliage components
Experimental Results
Quantitative Performance (Eight Datasets):
| Dataset | OA (%) | FA (%) | WA (%) | F1 Score | mIoU (%) |
|---|---|---|---|---|---|
| Spruce | 92.20 | 99.18 | 97.62 | 0.923 | 93.70 |
| Aspen | 90.80 | 98.67 | 89.50 | 0.907 | 92.95 |
| Poplar | 86.35 | 98.78 | 88.80 | 0.855 | 85.70 |
| Birch | 98.05 | 99.74 | 90.81 | 0.912 | 96.92 |
| Pine | 96.01 | 99.95 | 99.64 | 0.959 | 92.20 |
| Maple | 97.34 | 99.51 | 97.29 | 0.973 | 94.82 |
| Larch | 92.43 | 97.21 | 78.66 | 0.791 | 78.21 |
| Tropical | 94.69 | 97.10 | 91.09 | 0.896 | 89.96 |
Comparison with State-of-the-Art Methods:
| Method | Tropical OA (%) | Tropical mIoU (%) | Birch OA (%) | Birch mIoU (%) |
|---|---|---|---|---|
| LWCLF | 92.45 | 87.23 | 94.12 | 89.45 |
| LeWoS | 91.88 | 86.91 | 93.56 | 88.76 |
| FWCNN | 94.26 | 89.24 | 96.78 | 95.18 |
| SPTNet | 94.69 | 89.96 | 98.05 | 96.92 |
Efficiency Comparison:
| Method | Training Time/Epoch | Convergence Epochs | Model Size | Inference Time (50k points) |
|---|---|---|---|---|
| PointNet++ | ~15s | 245 | Large | >10,000 ms |
| Point Transformer | ~45s | 90 | Large | >60,000 ms |
| PointBert | ~15s | 102 | Large | >60,000 ms |
| PointMLP | ~10s | 198 | Medium | ~8,000 ms |
| SPTNet | ~8s | 48 | Small | ~3,391 ms |
Key Findings
Ablation Studies:
- SpConv vs. Transformer: Removing SpConv blocks causes larger accuracy drop than removing Transformer blocks, indicating local geometric features are crucial for woody/foliage discrimination.
- Feature Importance: NDO features contribute more than MDC features; combining both yields optimal results (OA improvement of 2-3% over using coordinates only).
- Backbone Comparison: SPTNet outperforms PointNet++, DGCNN, Point Transformer, and PointBert on all test datasets while maintaining 3-6× faster training speed.
Robustness Analysis:
- Occlusion Resistance: Maintains >90% OA even with 40% random point masking; degrades gracefully at 60-80% masking (OA drops to ~92% and ~77% mIoU at 80% masking).
- Cross-Species Generalization: Successfully handles both coniferous (Pine: 99.64% WA) and broadleaf species, as well as complex tropical trees with irregular structures.
Adaptive vs. Fixed Radius:
- Adaptive radius strategies (minimum entropy for MDC, Otsu for NDO) eliminate manual parameter tuning while achieving comparable or better accuracy than manually optimized fixed radii (0.1-0.5m range tested).
Sensor Independence:
- Pure geometry-based approach (no radiometric features) enables seamless application to data from different LiDAR sensors without recalibration or retraining for specific wavelength characteristics.
Limitations and Future Work
- Voxel Resolution Sensitivity: Performance depends on voxel size selection (0.02m used); smaller voxels improve accuracy but increase computational cost.
- Scale Constraints: Currently tested at single-tree level; extension to plot-scale processing with multiple trees and ground points requires further development.
- Occlusion Handling: While robust to moderate occlusion (up to 60%), severe occlusion (>80%) significantly degrades performance due to loss of neighborhood geometric information.
- Future Directions: Extension to airborne LiDAR data, semantic segmentation of urban scenes, and integration with instance segmentation for complete forest inventory workflows.

I am currently a Ph.D. candidate at the Ai4City-Lab, Urban Governance and Design Thrust, Society Hub, The Hong Kong University of Science and Technology (Guangzhou), under the supervision of Prof. Wufan Zhao and Prof. Yuan Liu. Prior to this, I obtained my Master’s degree from the School of Geospatial Engineering and Science, Sun Yat-sen University, where I was advised by Prof. Wuming Zhang and Prof. Yiping Chen.
My research focuses on 3D visual perception, intelligent interpretation and processing of point cloud data, and multi-modal urban foundation models. I am particularly interested in bridging geometric understanding with semantic reasoning in large-scale urban environments, with an emphasis on open-vocabulary learning, training-free paradigms, and cross-modal fusion between 2D and 3D data.
My goal is to develop scalable, interpretable, and generalizable AI systems for urban analysis, enabling applications such as digital twin construction, urban scene understanding, and intelligent infrastructure management.