UniD-Shift: Towards Unified Semantic Segmentation via Interpretable Share-Private Multimodal Decomposition
May 8, 2026·,,,,,,·
2 min read
Shuai Zhang
Zhecheng Shi
Zhuxiao Li
Jing Ou
Tengxi Wang
Yuan Liu
Wufan Zhao
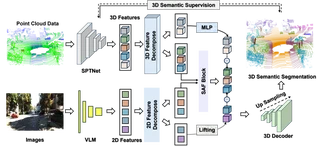 UniD-Shift overall architecture: SAM-based 2D encoder + SPTNet-based 3D encoder with shared-private feature decomposition and Shared Attention Fusion (SAF)
UniD-Shift overall architecture: SAM-based 2D encoder + SPTNet-based 3D encoder with shared-private feature decomposition and Shared Attention Fusion (SAF)Abstract
Semantic segmentation of large-scale 3D point clouds is crucial for applications such as autonomous driving and urban digital twins. However, the sparse sampling pattern of LiDAR and the view-dependent geometric distortion in image observations complicate cross-modal alignment and hinder stable fusion. Inspired by the fact that 2D images captured by cameras are representations of the 3D world, we recognize that the features learned from 2D and 3D segmentation share some common semantics, while other aspects remain modality-specific. This insight motivates a unified multimodal framework for joint 2D-3D semantic segmentation. We combine a SAM-based vision encoder with a SPTNet-based geometric encoder to extract complementary semantic and geometric representations. The resulting features from both modalities are explicitly decomposed into shared and private subspaces, where the shared components summarize semantic factors common to both domains, and the private components preserve properties that are unique to each modality. A lightweight attention-based fusion module aggregates the shared features into a consistent cross-modal representation, and a regularized training objective ensures both semantic alignment and subspace independence. Experiments on the SemanticKITTI and nuScenes benchmarks demonstrate consistent improvements in segmentation accuracy over representative multimodal baselines, accompanied by competitive computational efficiency. Cross-domain evaluation on nuScenes USA-Singapore shows stable performance under distribution shifts, demonstrating strong generalization.
Type
Publication
arXiv preprint arXiv:2605.07356
Highlights
- Unified Multimodal Framework: Joint 2D-3D semantic segmentation achieving high single-domain accuracy and strong cross-domain generalization through structured feature interaction.
- Shared-Private Decomposition: Explicit disentanglement of modality-invariant and modality-specific representations, improving semantic alignment and interpretability.
- SAM + SPTNet Dual-Branch Design: Integrates SAM-based vision encoder with sparse convolution-transformer backbone to combine semantic richness and geometric precision.
- SOTA Performance: 81.0% mIoU on nuScenes validation, 81.2% on nuScenes test, and 71.8% on SemanticKITTI, outperforming 2DPASS, CSFNet, and other multimodal fusion baselines.
- Cross-Domain Robustness: 74.5% mIoU on nuScenes USA→Singapore cross-domain benchmark, demonstrating strong generalization under distribution shifts.
- Interpretable Fusion: Attention-based Shared Attention Fusion (SAF) with Gram alignment and decorrelation regularization ensures stable optimization and meaningful feature separation.
Method Overview
The proposed UniD-Shift framework adopts a dual-branch architecture:
- 3D Branch: SPTNet backbone (sparse convolution + transformer) extracts hierarchical geometric features from LiDAR point clouds.
- 2D Branch: SAM-based vision encoder provides semantically rich visual representations from RGB images.
- Shared-Private Decomposition: Features from both modalities are decomposed into shared (modality-invariant semantics) and private (modality-specific) components.
- Shared Attention Fusion (SAF): The shared components are fused via cross-attention (3D→2D query) to produce a consistent multimodal representation.
- Regularized Training: Gram matrix alignment encourages shared consistency, while decorrelation loss promotes subspace independence.
Key Results
| Benchmark | Metric | UniD-Shift |
|---|---|---|
| nuScenes Validation | mIoU (%) | 81.0 |
| nuScenes Test | mIoU (%) | 81.2 |
| SemanticKITTI Validation | mIoU (%) | 71.8 |
| nuScenes USA→Singapore | mIoU (%) | 74.5 |
The framework achieves competitive computational efficiency with 240ms inference latency on SemanticKITTI, demonstrating a practical balance between accuracy and speed.
Citation
@misc{zhang2026unidshift,
title={UniD-Shift: Towards Unified Semantic Segmentation via Interpretable Share-Private Multimodal Decomposition},
author={Shuai Zhang and Zhecheng Shi and Zhuxiao Li and Jing Ou and Tengxi Wang and Yuan Liu and Wufan Zhao},
year={2026},
eprint={2605.07356},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2605.07356},
}