Point and voxel cross perception with lightweight cosformer for large-scale point cloud semantic segmentation
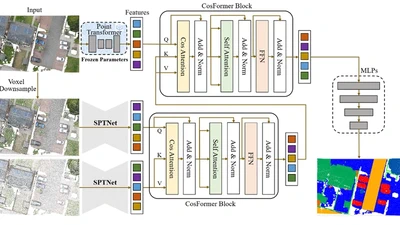
This paper proposes PVCFormer, a cross-attention architecture combining point and voxel representations with CosFormer for efficient large-scale outdoor point cloud semantic …
